AI Forecasting is Quietly Reaching Human Expert Level
Try it out yourself

Modern AI forecasting systems are now approaching—or even matching—top human forecasters on major benchmarks. This unlocks a new class of “forecasting-at-scale” tools for individuals, firms, and governments.
Over Christmas, I built this app, which implements one such approach. Test it for yourself. Pick a topical question that’s in the news, or something really niche that only you’re interested in.
Oracle Bones to Tetlock
Long before forecasting tournaments, the Shang kings of ancient China were running a kind of state-sponsored forecasting operation. Questions of war, harvests and ritual timing were written onto turtle shells and ox bones. Heat was applied until cracks formed, and specialists interpreted the patterns. These “oracle bones“ represent some of the earliest attempts to divine the future, dating from roughly 1600–1050 BCE. Of course, the Ancient Greeks looked to the Oracle at Delphi for similar guidance.
Our present-day oracles might be Rory Stewart and Alastair Campbell, Nate Silver, or your favourite Substacker. Much like our ancestors, we still have an innate dislike of uncertainty. We search, we interpret, we tell stories, and we’re drawn to people who seem to see further than the rest of us, or can at least “make sense” of a chaotic world.
Philip Tetlock brought rigour to the study of forecasting. His earlier research, Expert Political Judgment (2005), had shown that supposed experts weren’t much good at prediction, and confident pundits were worst of all. The now-famous IARPA forecasting tournaments, launched in 2011, measured the accuracy of forecasters on a wide range of geopolitical questions. Perhaps the most notable finding from this research was that a small slice of ordinary people were consistently prescient.
These “superforecasters” had a few consistent behaviours: the ability to step back and assess the “base rates”, breaking big geopolitical questions into smaller conditional ones, putting numbers on uncertainty early, and then updating those numbers frequently as new evidence arrives. Tetlock and Dan Gardner laid out these findings in the bestseller Superforecasting: The Art and Science of Prediction (2015).
What if we could automate superforecasting? The past two years of research suggest we can — or at least that we’re very close.
AI’s Steady Advance Towards Superforecasting
The progress over the past two years has been rapid. Here’s Gemini’s Nano Banana image model’s graphing of this progress.
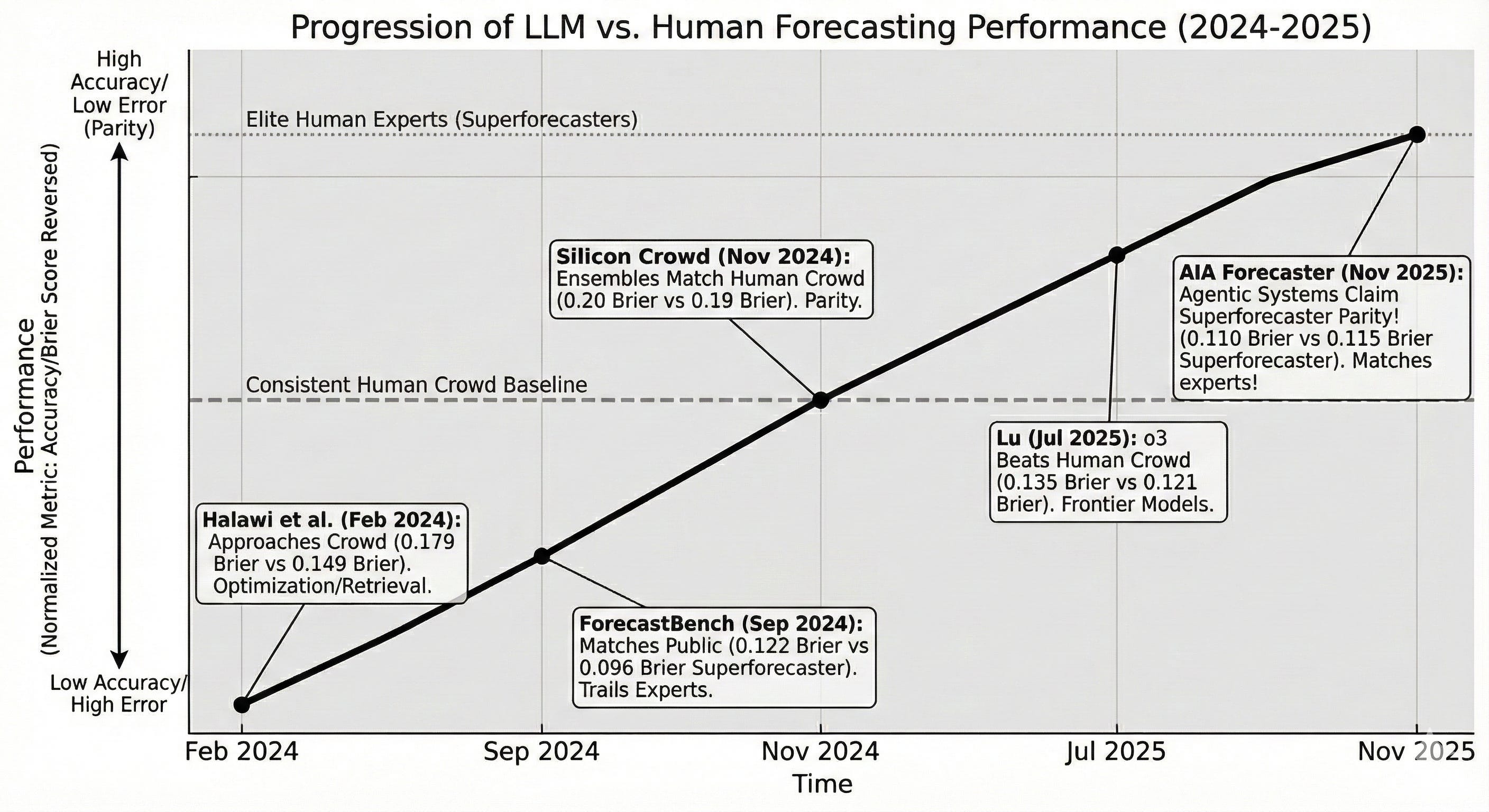
Here are the key papers.
Halawi et al. (Feb 2024) — “Approaching Human-Level Forecasting with Language Models”
The first serious attempt to build an end-to-end AI forecasting system. Combined retrieval-augmented generation with forecast aggregation across multiple LLM calls. Key finding: a single LLM system approached but didn’t match human crowd performance on competitive forecasting platforms. Established the baseline everyone else would try to beat.
ForecastBench (Sep 2024) — Karger, Tetlock et al.
Created the gold-standard benchmark for AI forecasting. Unlike static tests that models can memorise, ForecastBench continuously generates new questions about future events—eliminating data leakage concerns entirely. Initial results showed LLMs still underperforming superforecasters (Brier scores of ~0.11 vs. 0.09). (See here for their latest blog on AI vs superforecaster performance).
Wisdom of the Silicon Crowd (Nov 2024) — Schoenegger, Tetlock et al.
An important conceptual breakthrough: if crowds of humans beat individual humans, do crowds of LLMs beat individual LLMs? They find it does. An ensemble of 12 different LLMs matched the performance of 925 human forecasters in a three-month tournament. This established that “wisdom of the crowd” effects apply to AI systems.
Lu (Jul 2025) — “Evaluating LLMs on Real-World Forecasting”
Tested frontier models (GPT-4.1, o3-pro, Claude 3.6, DeepSeek-R1, Qwen3) on 464 Metaculus questions. Finding: frontier models now match or beat the average human forecaster, though they still lag behind elite experts. Also discovered that models perform notably better on politics than economics—suggesting they’re better at pattern-matching public events than modelling complex systems.
AIA Forecaster (Nov 2025) — Bridgewater AIA Labs
The current state of the art in the published literature. Three innovations: (1) agentic, multi search over high-quality sources; (2) a supervisor agent that reconciles disagreements between multiple forecaster agents; (3) statistical calibration to fix LLMs’ tendency to hedge toward 50%. Result: the first verified AI system to match superforecaster performance on ForecastBench. On harder liquid prediction markets, the AI still trails consensus. Though the AI along with the latest market price beats the market alone, demonstrating that AI provides genuinely additive information.
Commercial models
Worth highlighting too are commercial systems such as Mantic and Cassi, which are very close to — or on a par with — the best human forecasters on Metaculus/ForecastBench competitions. E.g. see coverage of Mantic here. You can also track the relative performance of a whole suite of LLMs including bespoke forecasting models from commercial providers on the Forecasting Research Institutes ForecastBench.
Delphi — Try It Yourself
Inspired by this research, I spent a few weekends building a forecasting app that draws on the Bridgewater framework in particular - Delphi.
Here’s how it works:
Enter a forecasting question — You provide any question about the future
AI reformats it — The system converts it into a binary prediction question with clear resolution criteria
10 agents research independently — Each agent searches the web and generates its own forecast
Supervisor synthesises — A supervisor agent reviews all predictions, identifies disagreements, conducts follow-up research if needed, and creates a final aggregate prediction
Or here it is laid out by Nano Banana…
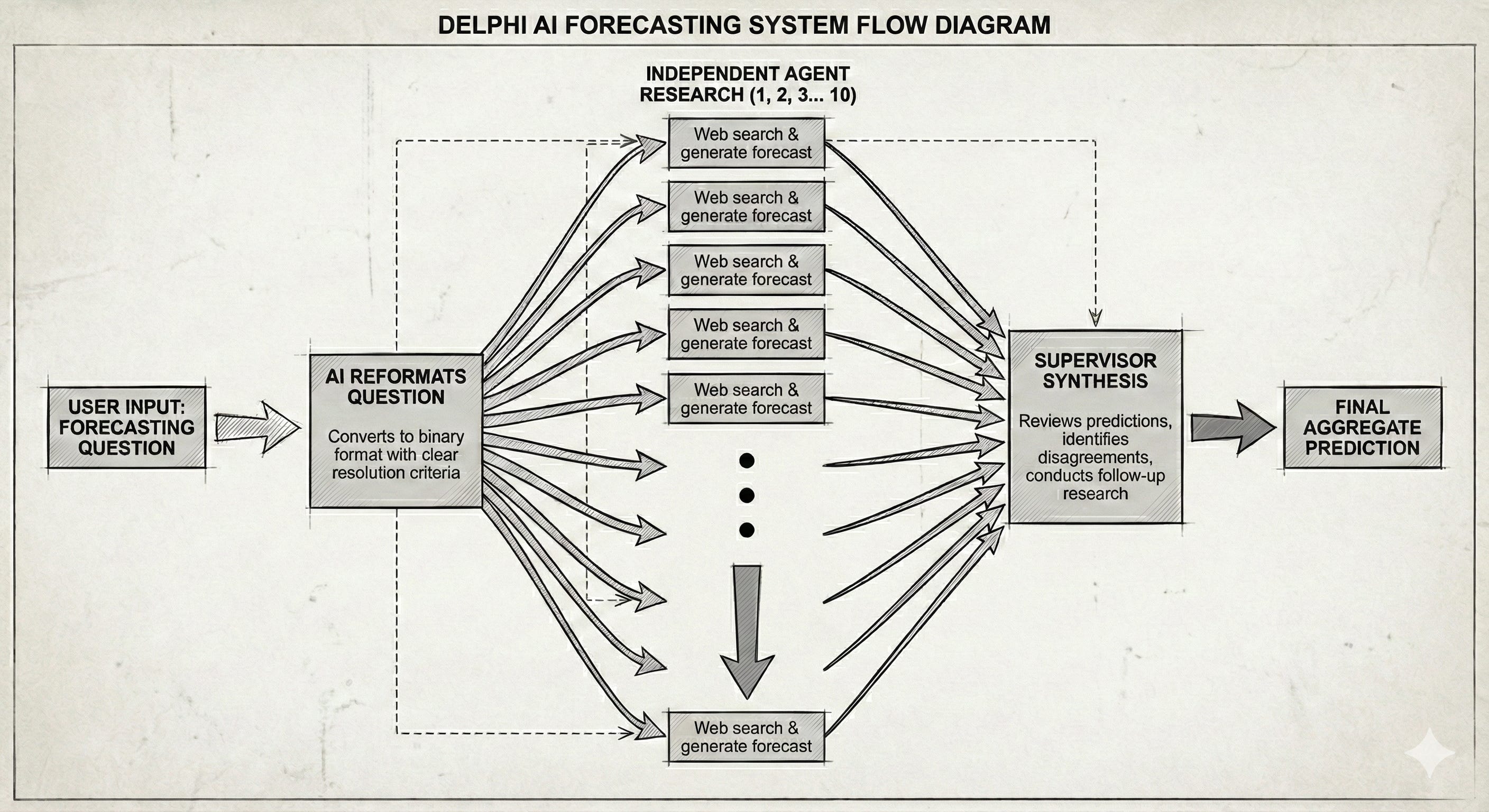
Think of it as having a panel of analysts who each independently research the question before a senior analyst synthesises their views.
Note: The public version of the tool is limited to GPT-5 nano with “low” search and reasoning depth to manage costs. I’m planning a “bring your own API key” feature for those who want to run deeper analyses.
What did people want to predict?
Since I shared it on LinkedIn, there have been 300 predictions. Most of these are related to UK and US politics. E.g. whether Keir Starmer will still be PM at the end of 2026 (a coin toss) or whether Trump would take Greenland by force (~5%). But people also used it for niche forecasts.
These hint at what bespoke ‘on the fly’ forecasting can offer. A few favourites:
Will house prices within 1km of Streatham Common be 5% higher in 2027? (44%)
Will the UK ban trail hunting in England and Wales? (~36%)
Will Ireland’s construction cost index be lower in 2030? (~21%)
Will the UK’s Medicines and Healthcare products Regulatory Agency (MHRA) grant marketing authorisation for a psilocybin-containing medicine by 2031 (24%)
It’s the ability to run niche personal forecasts that’s perhaps the most interesting part of this.
So how accurate is it?
I haven’t rigorously tested the tool. The point was to make it an accessible way to run your own forecasts based on a solid methodology.
However, I’ve been comparing it to Polymarket for a couple of key world events. Below is the prediction for the fall of the Iranian Regime from Polymarket and very similar question run on Delphi. Polymarket seems to have reacted faster to the news headlines while Delphi remained much more anchored.
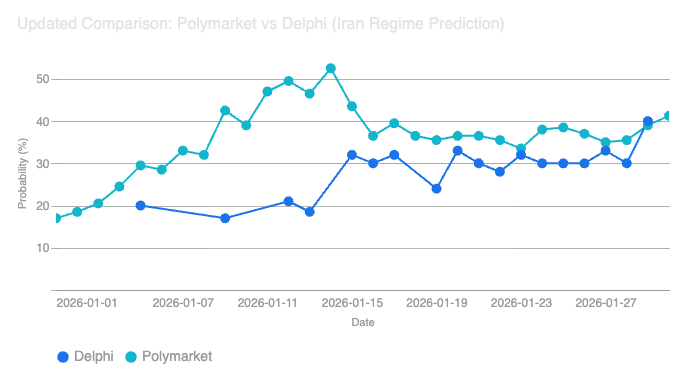
I interpret this as the AI — this one at least — putting greater weight on base rates. We also see this with various forecasts about the US taking over Greenland in 2026 that were run on the AI tool (e.g. here and here). None gave a prediction above ~8-10% of the US acquiring or attacking Greenland, while the Polymarket got to 20% in mid January.
But anchoring to base rates is not always optimal. A forecast for whether Craig Guildford would resign as Chief Constable of West Midlands Police, run at lunchtime on January 16th was at 27% (here’s the background story). At this point however, the writing was on the wall and he retired with immediate effect a few hours later. Though in the strictest interpretation I guess he hadn’t resigned?
Implications
The bottleneck to good forecasts is removed
Until now, high-quality predictions required either expensive human superforecasters or liquid prediction markets with significant trading volume. Depending on the quality of AI model and the depth of reasoning a prediction on Delphi costs between $0.20 and $2.00 and takes 30 seconds to 5 minutes and can be on a topic that only you care about.
Automated and liquid predictions across far more topics
Markets like Metaculus, Polymarket, and Kalshi are powerful but questions need enough participants to generate reliable prices. AI forecasters can serve as market-makers of a sort—providing initial liquidity and baseline estimates that attract human traders. As regulatory changes open up prediction markets further, expect AI systems to be trading many of these markets directly—just as algorithmic trading provides liquidity in traditional financial markets.
Bespoke Polymarket for your organisation
If you’re Donald Trump you can open Polymarket and it’ll give you a pretty good ‘outside view’ on what the market expects to happen across a wide range of topics relevant to you. But for most companies and governments, that’s not the case. But imagine you’re a business that can now have a dashboard of prediction markets for a specific regulatory change that will impact your strategy, whether your competitor’s will enter a new market and much else besides. Or as a government minister, you get an outside view on whether your reforms are going to meet the manifesto pledges you made or falls short. The more politicians focus on indicators of policy success and less on polls, the better.
The many barriers to changing organisational decision making
But it would be naive to think that new tools — even very smart ones — will change how organisations make decisions. Just as important as proving the accuracy of these tools is knowing what questions a decision maker is actually interested in and integrating these indicators in the decision making processes and frameworks of business and government.
The ancient Shang rulers interpreted cracked turtle shells; we prompt language models. The difference is that ours might actually work — and at twenty cents a go, anyone can consult the oracle.
Next up I’m planning to run a version of the prediction AI in the Metaculus AI forecasting tournaments. I’ll cover that in a future post.